Breaking Down Barriers - Part 4: GPU Preemption
This is Part 4 of a series about GPU synchronization and preemption. You can find the other articles here:
Part 1 - What’s a Barrier?
Part 2 - Synchronizing GPU Threads
Part 3 - Multiple Command Processors
Part 4 - GPU Preemption
Part 5 - Back To The Real World
Part 6 - Experimenting With Overlap and Preemption
Welcome back! For the past two articles we’ve been taking a in-depth look at how a fictional GPU converts command buffers into lots of shader threads, and also how synchronization of those threads affects the overall performance of the GPU. Up until now, we’ve really only been discussing things in terms of how a single application would use a GPU. This keeps things relatively simple, but in reality there’s almost never just one application that has an entire GPU to itself. Instead, the OS arbitrates multiple applications that all utilize the GPU as a shared resource, just like it does for other shared resources like the CPU or system memory. Doing it this way can make things more complex for the GPU and its driver, but it’s really important for enabling responsive multi-tasking between multiple applications that rely on the GPU for rendering (which is something that you even see on consoles these days!). It’s also critical if the OS itself relies on the GPU for rendering elements and compositing them together, which is something that Windows has done ever since the introduction of the Desktop Window Manager (DWM) with Windows Vista. In this article I’m going to talk a bit about the implications that multi-tasking can have on a GPU, and how that can potentially tie back into multiple command processors.
Fighting Over a GPU
As I was saying earlier, in 2018 it’s no longer a safe assumption that only a single application will be using the GPU at a given point in time. There are web browsers or other productivity applications that might be using Direct2D to render UI elements. There might be streaming or voice chat applications that need to use the GPU to encode video and audio. Or there might be a VR composition service that needs always present to the headset at 90Hz, even if the VR application itself is failing to render at that framerate. Serving multiple applications is probably doable for the older MJP-3000 and its single command processor, at least as long as no single application is submitting a significant amount of work at any given time. It’s pretty reasonable to expect that a little logic in the OS or driver could work for this: the driver could maintain a queue (or multiple queues) in software, and each application could submit their command buffers to this software queue. Then whenever the GPU is idle, the driver can pick a command buffer from its queue and submit it to the GPU where it can actually get executed. So 3 apps might share the GPU like this:

Here we have two timelines: one showing what’s enqueued in the driver (on the bottom), and one showing what’s currently executing on the GPU (top). So the red app submits a command buffer which executes for a while, then the GPU goes idle again. Then the green app submits another command buffer which executes for longer, and eventually the blue app submits a final command buffer that completes very quickly. In this scenario our setup works fine: everybody is able to use the GPU when they need it, which means that the latency for any app’s submission is roughly equal to the time it takes to complete the work on the GPU. On the flip side of things, it’s not hard to imagine a scenario where things don’t work out so nicely:

This time, the red app decided to really hog the GPU for a while. This caused the submission from the green app to sit in the driver’s queue for a long time, severely increasing the latency from submission to completion. In fact it waited so long that the blue app submitted while the green app was still waiting, causing the driver’s queue to have two submissions queued at the same time. The latency is particularly unfortunate for the blue app, whose submission had barely any work and completed very quickly once it actually had a chance to run. It would be really unfortunate if the blue app was something critical, like the operating system’s composition engine, or a browser that the user is currently interacting with.
To properly accommodate high-priority applications using the GPU, what we really want is some form of preemption. We essentially want to be able to interrupt an app’s workload that’s being executed by the GPU, so that we can sneak in the high-priority work without having to wait for the GPU to go idle. With the older architecture of the MJP-3000, the GPU can only be working on one command buffer at a time, and the command processor always executes that entire command buffer to completion. Therefore the easiest way to do this would be to have the OS or driver try to split an app’s submission into multiple smaller command buffers. This would effectively give the driver finer granularity to work with in its submission queue, and could potentially allow a high-priority submission to get in earlier:
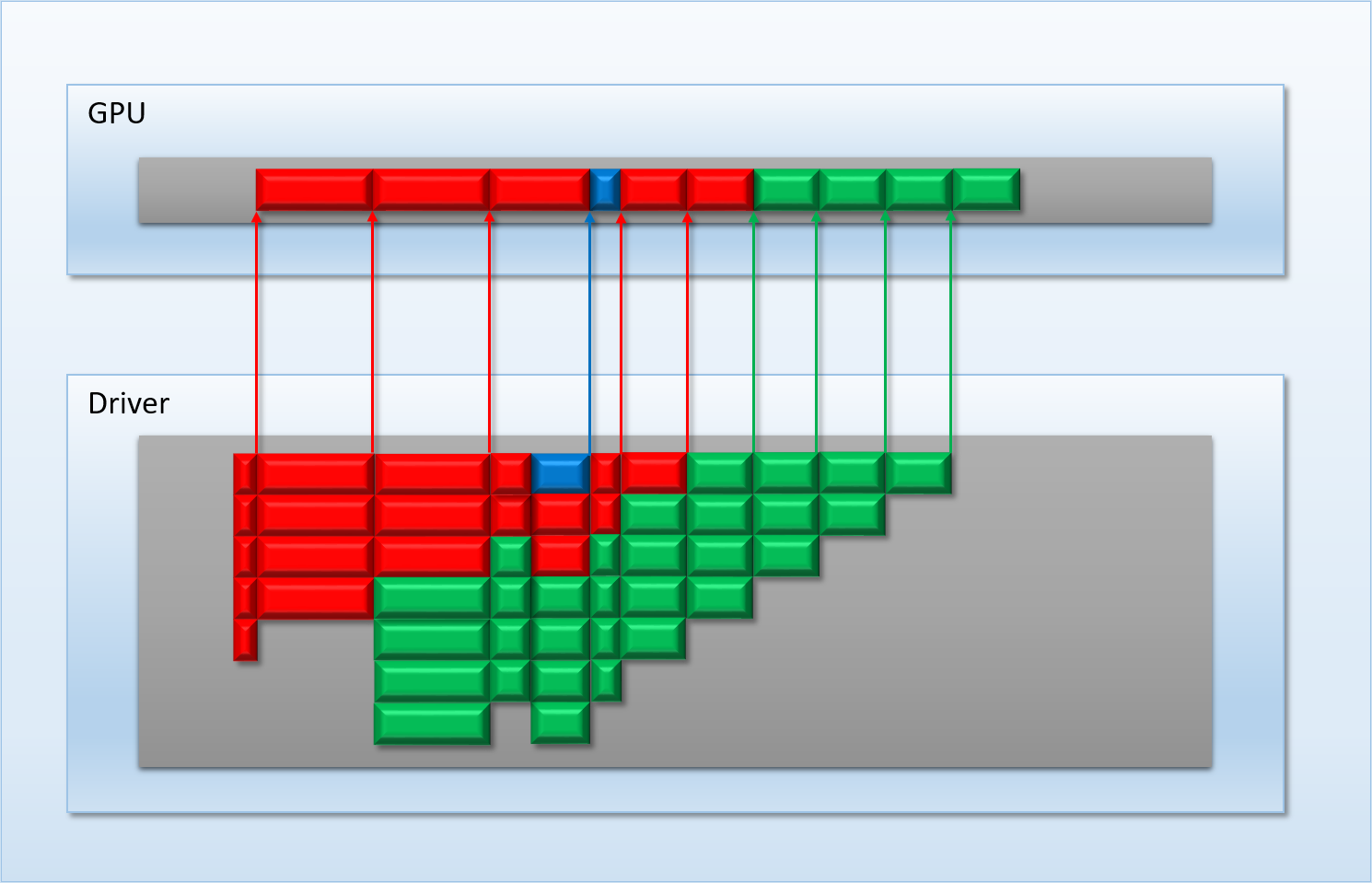
This time the driver has split up the red app’s workload into 5 command buffers, and the green app’s workload into 4 command buffers. Having more command buffers means that the driver’s queue is much deeper than before: at worst it now has 7 pending submissions simultaneously queued. However this also gives the driver more opportunities to switch to a higher-priority submission. This time around the blue submission is treated as high priority, which causes the driver to immediately move it to the top of the submission queue, which also displaces the other submissions. Thanks to the smaller command buffer size, the blue submission only needs to sit in the queue for a little bit before it has a chance to run on the GPU. This reduces the latency compared to the earlier case, where each app just submitted a single combined command buffer.
With the setup I just described, we effectively have command buffer-level preemption. This means that our preemption granularity is tied to our command buffer granularity, and the preemption latency of a high-priority task is tied to the length of execution of any single command buffer. That last part might make you want to ask, “how can the OS or driver know how long a particular command buffer will take?”. And of course the short answer is that “it can’t”. Even a command buffer with a single command can potentially take a very long time to completely execute through the entire pipeline, since that one command might be “dispatch 5 billion threads”. Or it might be “dispatch 1024 threads of a really long shader program that takes 10 milliseconds to finish”. This leaves the driver with an impossible task, since the best it can do is use heuristics in an attempt to chop up an app’s command stream into bite-sized chunks.
The other problem with this approach is that it can potentially lead to lower throughput even when no preemption occurs. For instance, imagine if a GPU needed to completely flush at the end of every command buffer. In that case, splitting things up into lots of small command buffers would lead to lots of otherwise unnecessary sync points where multiple draws or dispatches can’t overlap with each other. Another issue to consider is how to handle GPU state that can be set by the command buffer. The fictional MJP series of GPU doesn’t really have much state to speak of, since it only handles compute shaders. But on a real GPU that supports a full D3D/GL/Vulkan rasterization pipeline there’s all kinds of state that’s modifed by individual commands. These include things like the viewport transform, bound render targets, depth buffer states, and the currently-bound shader programs for each stage. If the hardware is not capable of saving and restoring these states when switching command buffers, it may fall to the the driver to generate additional commands for restoring the expected rendering state. This can potentially add both GPU and CPU overhead for each command buffer switch, adding a further complication to the decision regarding how finely to chop up command buffers.
Having the Hardware Help Us Out
If we really want to avoid latency for high-priority jobs, we’ll have to do better than a driver-managed command buffer queue in software. Fortunately, there’s a few possible ways that we could do better with some changes to the GPU hardware. Probably the most obvious option would be to modify the command processor so that it can support switching to a different command buffer before its current stream has finished. If it were able to do this in between individual commands, then we would call this command-level preemption. This sounds nice in theory, but depending on the specifics of the GPU it can get a bit complicated. You’d have to be careful to ensure that any of your synchronization commands will continue to work if preemption occurs between the dispatch and the following wait/flush command. On top of that, you would still have the same issues regarding saving and restoring GPU state when preemption occurs. Even if you get this working, your preemption latency is still going to depend on the maximum length of a wait/flush command, which in turn is going to be dictated by the maximum length of a single Draw or Dispatch. This means that if your high-priority command buffer gets submitted right as the GPU is cranking through an expensive full-screen pass (for instance, the tiled lighting compute shader in a deferred renderer), the high-priority submission might end up waiting a while before it can run.
Alternatively, another option to improve preemption latency would be to leverage the multiple command processors on a GPU like the newer MJP-4000. With multiple command processors, an app with heavy GPU workloads could hog one of the command processors all it wants, and a high-priority app could use one of the free command processors to sneak in some work without the other app even noticing. To do this effectively, we just need to tweak the rules that the thread queues will utilize for sharing the shader cores:
-
If only one queue has pending threads and there are any empty shader cores, the queue will fill up those cores with work until there are no cores left
-
If both queues have work to do and there are empty cores, those cores are split up based on the priority of the submissions being processed. If one queue has high-priority work and the other doesn’t, then the threads from the high-priority dispatch fill up as many shader cores as they can, with any remaining cores going to the threads from the other queue. If both queues have work with the same priority, then the cores are split evenly and assigned threads from both thread queues (if there’s an odd number of cores available, the top queue gets the extra core)
-
Threads always run to completion once assigned to a shader core, which means pending threads can’t interrupt them
Let’s now take a look at how this would work out in practice. In the following example, app A will launch 80 threads of shader A (red), which take about 100 cycles for each thread to finish. About 250 cycles into this process, app B will submit a high-priority command buffer that will dispatch 16 threads of shader B (green), which also take about 100 cycles to complete:

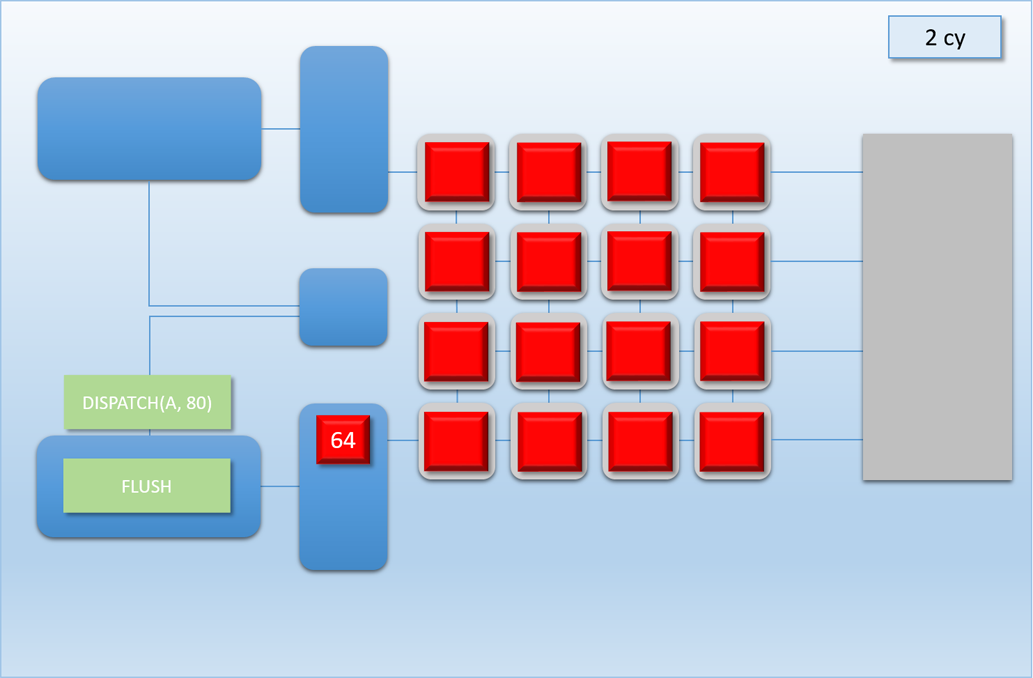
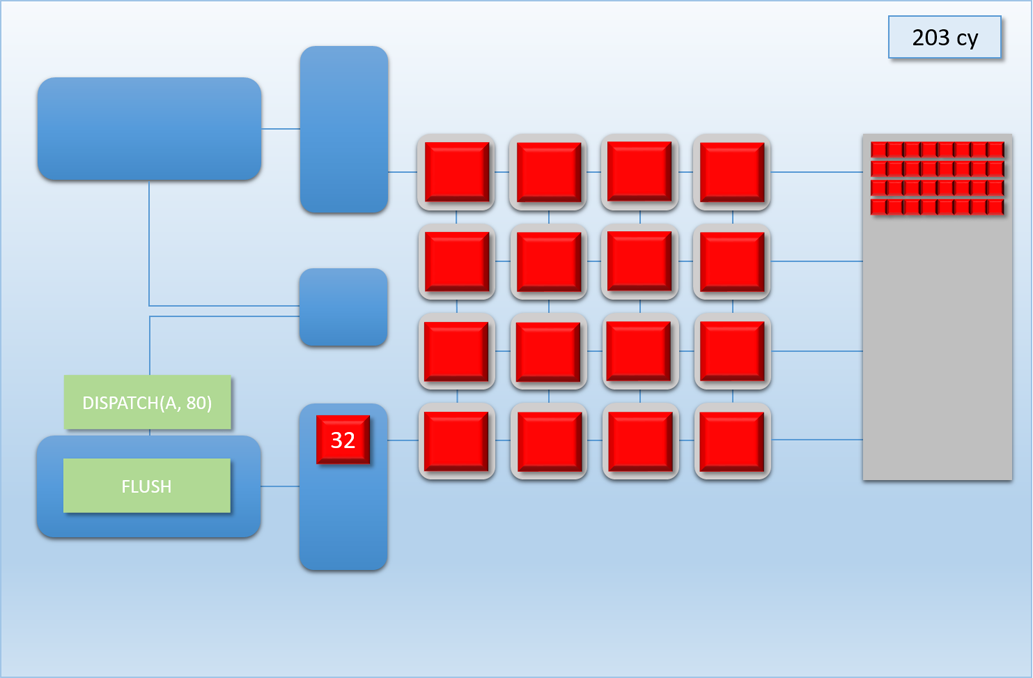
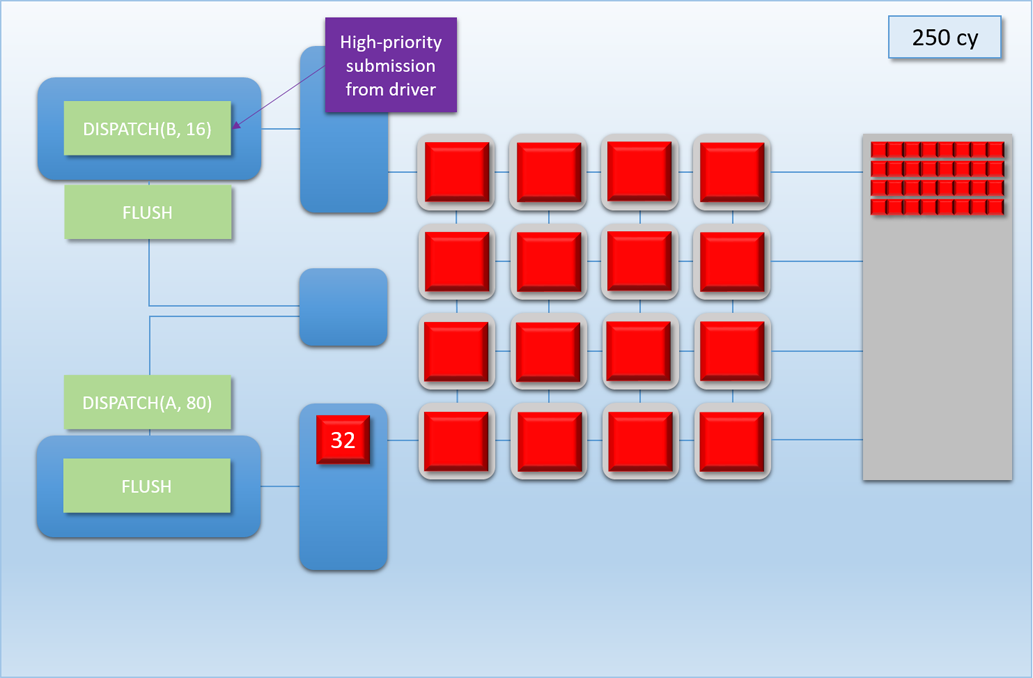
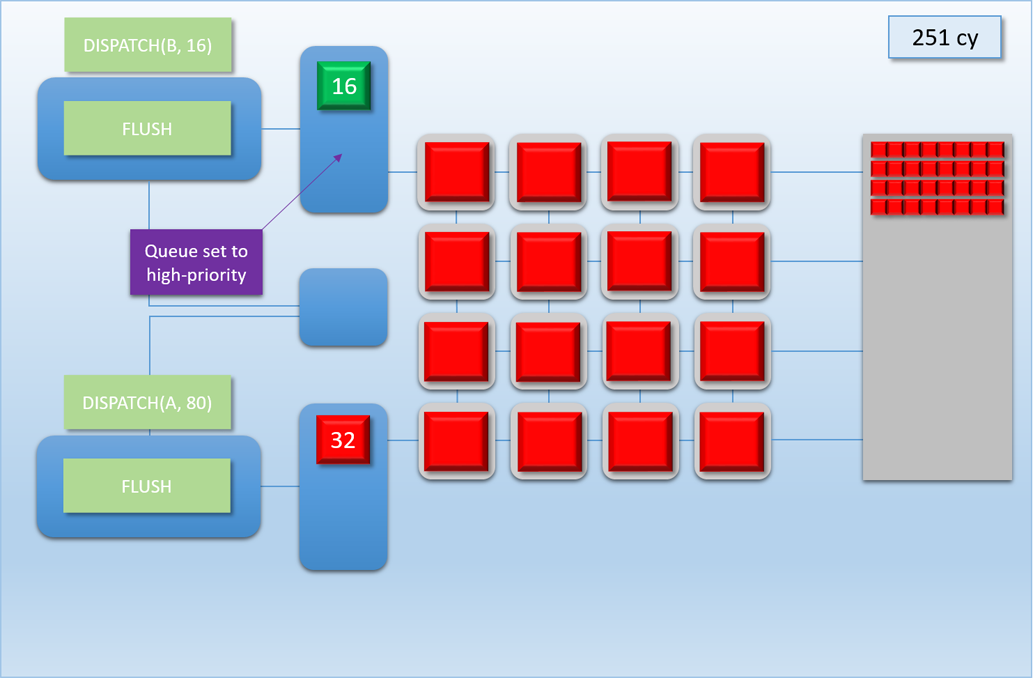
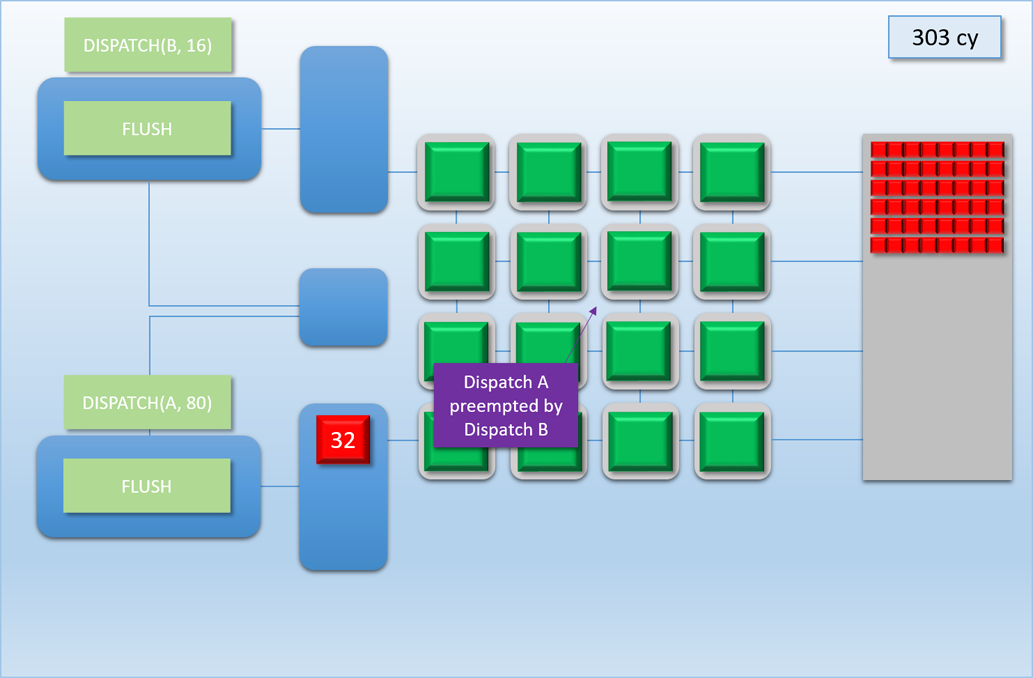
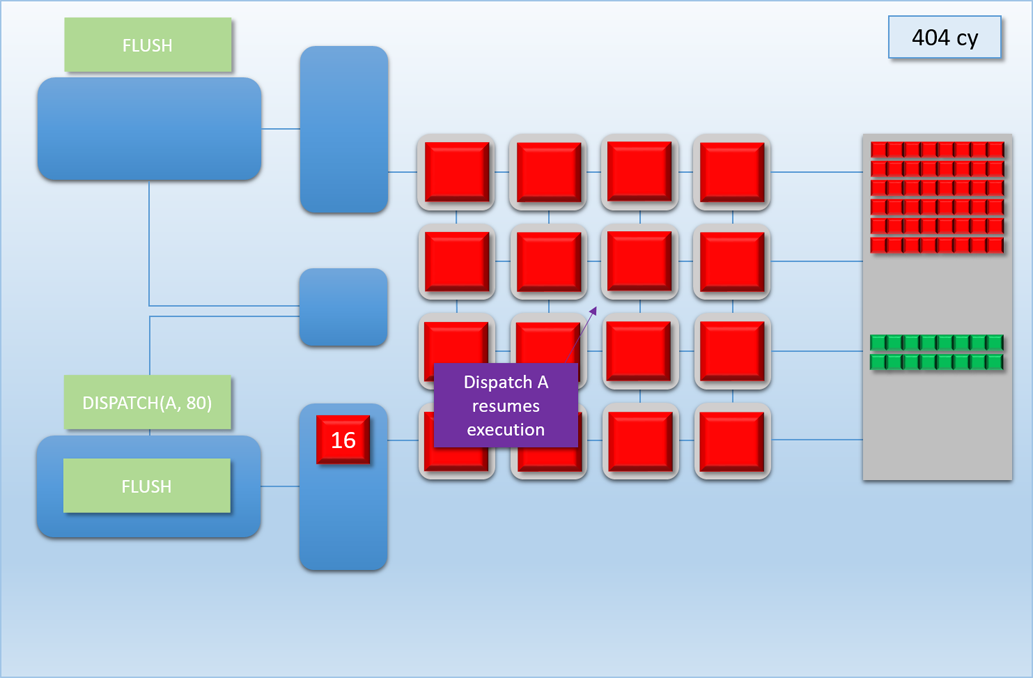
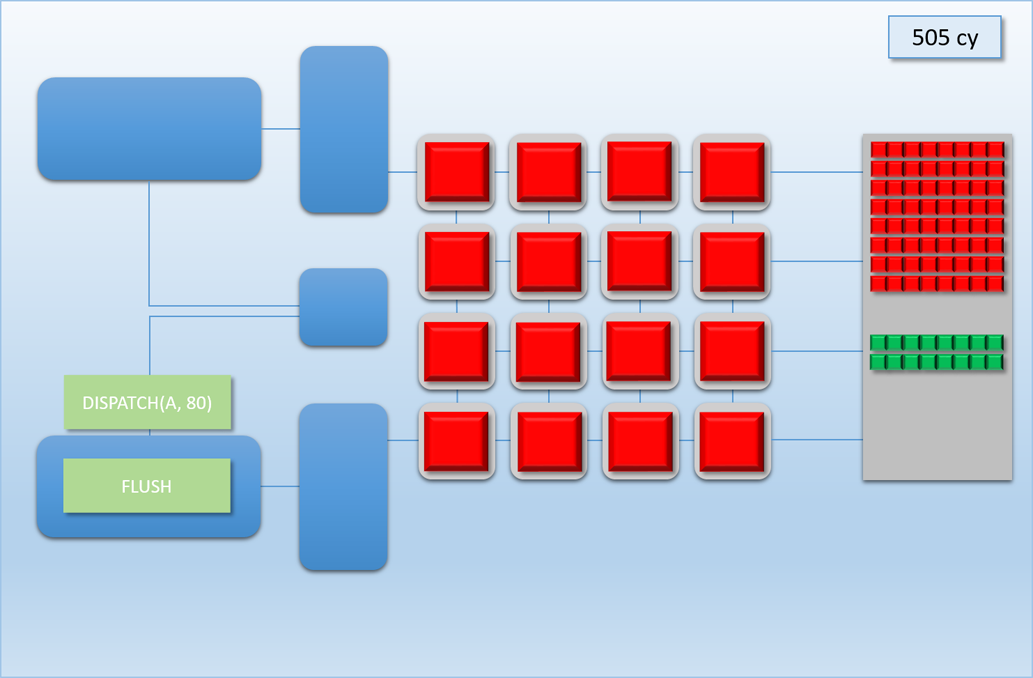
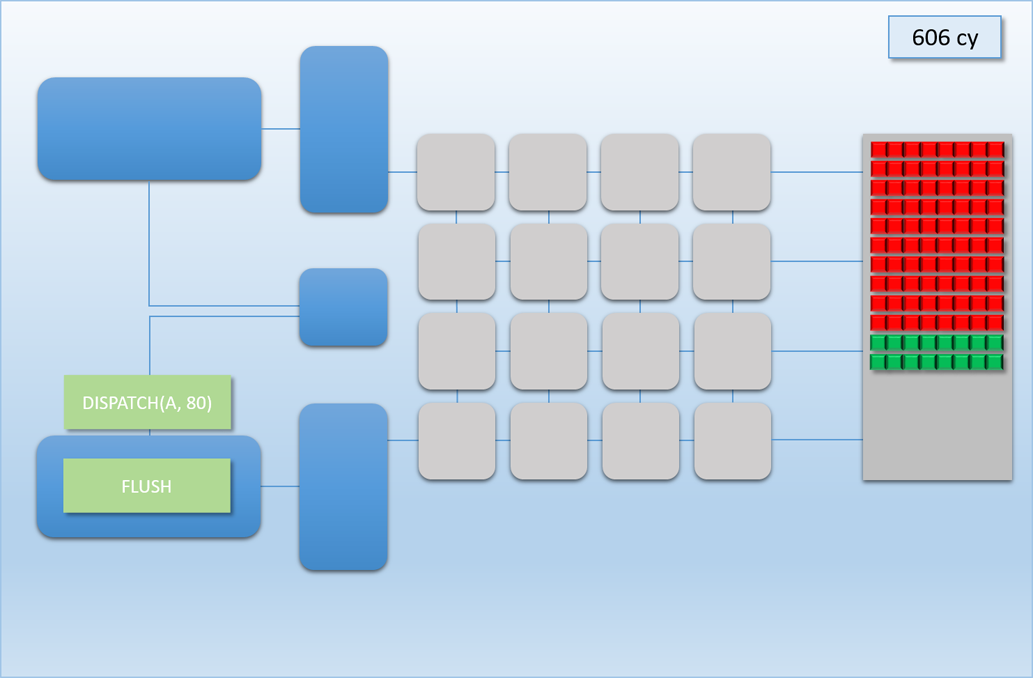
Thanks to the additional command processor and thread queue, the high-priority dispatch is able to enqueue its threads immediately in the second thread queue. This allows the threads to start executing about 200 cycles earlier than if it had to wait for dispatch A to completely finish, which demonstrates that we’ve successfully reduced latency for the high-priority task. Unfortunately dispatch B still had to spend about 50 cycles enqueued before its threads start executing on the shader cores, since the hardware has no ability preempt threads that have already started running. Therefore we can consider this to be thread-level preemption, since the granularity is equivalent to the length of a thread’s execution. However it’s important to note that since our fictional GPU has many shader cores (just like real GPU’s, which can have thousands), in some cases there’s no need for preemption at all. For instance, imagine if dispatch A and dispatch B both had 8 threads: in that case both dispatches could perfectly overlap with each other, essentially allowing ideal latency for the high-priority job without affecting the latency of the low-priority job. Therefore we would probably want to illustrate the CPU/GPU timeline like this:
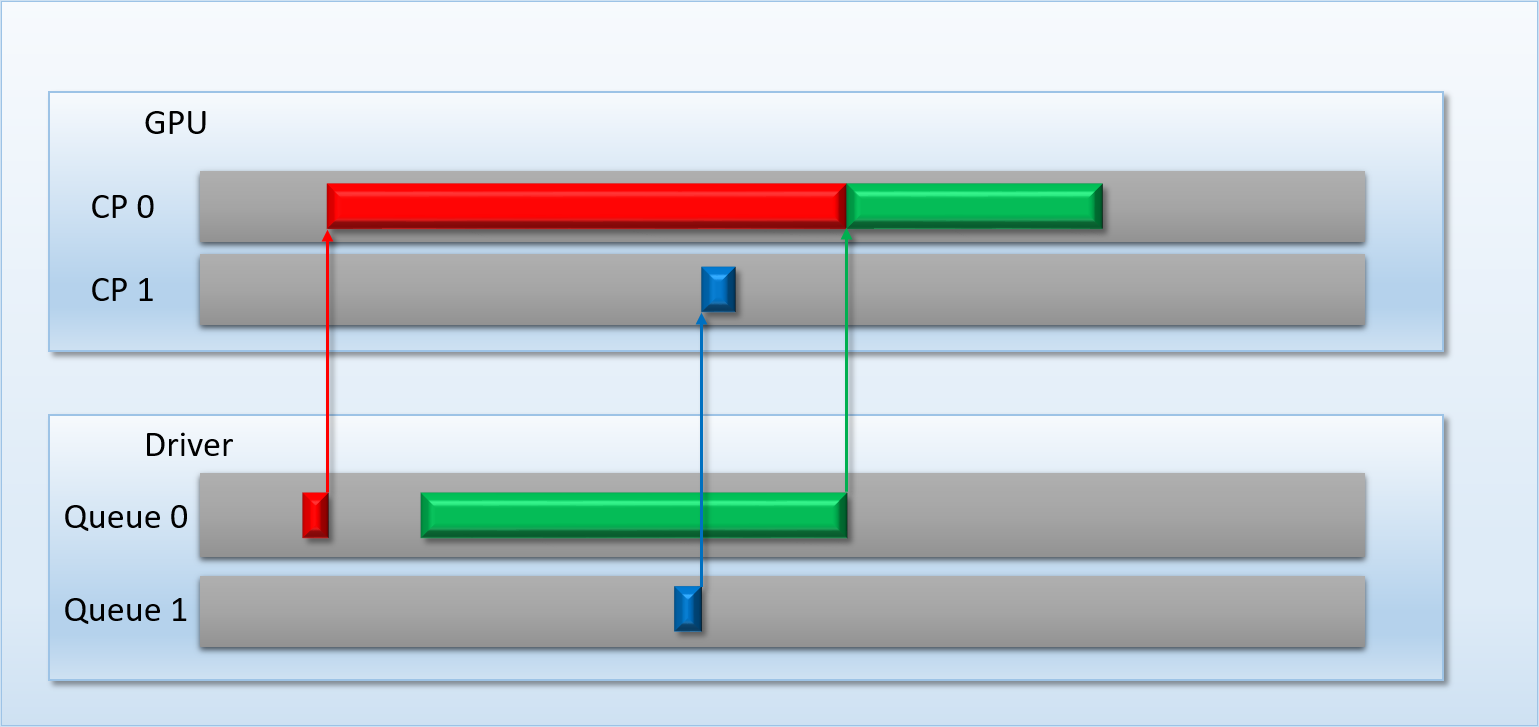
While it’s obvious how this could be useful for the case of an app like the Oculus compositor that needs to run its own high-priority job, it could also be useful within the context of a single app that wants to use the GPU for things other than graphics. Let’s say that a game wants to run some physics calculations on the GPU during its simulation update phase while the GPU is simultaneously running rendering commands from the previous frame. It wouldn’t be so great if the physics system had to wait around for a frame or so to get its results back from the GPU, and so it would make sense to submit a high-priority job to the extra command processor so that it can execute quickly.
With support for thread-level preemption, the only time our high-priority dispatch would get stuck waiting would be if the all of the shader cores were running threads that took a very long time to complete. If we wanted to avoid waiting in that case as well, we would need to essentially suspend threads that are already in-flight in order to allow high-priority threads to run without waiting for existing threads to finish executing. This would be considered instruction-level preemption, since our granularity would be at the level of a single instruction that executes on the shader core. This sort of preemption is very common on CPU’s, which are often capable of switching contexts in the middle of an instruction stream. On GPU’s a full context switch can be more impractical, since they typically work with large groups of threads that collectively require hundreds or thousands of registers!
Next Up
In Part 5, I’m going wrap up our discussion of multiple command processors and preemption by discussing some real-world GPU’s from Intel, AMD and Nvidia. I’m also going to give an overview of how D3D12 exposes command buffer submission, and also explain how Windows lets you view the low-level queuing and execution of command buffers via ETW and GPUView. See you then!
Comments:
MJP -
Thank you for pointing that out Andy, I goofed on that one! I re-worked the images to use 80 threads instead of 96, and now things work out the way they should. :) And yeah, what you’re saying is pretty much the exact reason I started writing these articles. Working with consoles is fantastic for learning all of these low-level details, but unfortunately that knowledge is locked away behind NDA’s. And then would I would look at the D3D12 API’s and programming guides for barriers, and wonder how how anybody without console experience would know *why* you need those barriers in the first place. I would have loved to use the PS4 GPU (or one of its PC cousins) as an actual real-world case study for the scenarios I bring up, but I don’t want to run afoul of NDA’s. So for now I’m sticking to my made-up GPU, and pointing to things explicitly mentioned in publicly-available documents.
#### [anon]( "notarealmailaddress@asyoucanseeclear.ly") -
AMD has released the GCN and Vega Whitepapers which you linked to in earlier posts but there also is the Register Reference Guide for SI, the linux amdgpu kernel driver and two Open Source Vulkan implementations (radv, xgl+pal). They contain all the information that you need to explain sufficiently how the hardware works IMO.
#### [Andy Robbins]( "raicuandi@gmail.com") -
Really great tutorial on how these things work. Looking back it’s hard to understand how this works purely from transition (data) barriers, since they don’t really make execution barriers explicit. For me it only became clear what’s going on after reading PS4 docs, but if those aren’t an option to someone, this series of posts is the next best thing. Spotted a mistake: the interactive demo loses 16 threads from Dispatch A at the same time 16 threads from Dispatch B get to execute. The total duration should be ~700 cycles not ~600.
#### [Breaking Down Barriers – Part 1: What’s a Barrier? – The Danger Zone](https://mynameismjp.wordpress.com/2018/03/06/breaking-down-barriers-part-1-whats-a-barrier/ "") -
[…] a Barrier? Part 2 – Synchronizing GPU Threads Part 3 – Multiple Command Processors Part 4 – GPU Preemption Part 5 – Back To The Real World Part 6 – Experimenting With Overlap and […]
#### [Breaking Down Barriers – Part 2: Synchronizing GPU Threads – The Danger Zone](https://mynameismjp.wordpress.com/2018/04/01/breaking-down-barriers-part-2-synchronizing-gpu-threads/ "") -
[…] a Barrier? Part 2 – Synchronizing GPU Threads Part 3 – Multiple Command Processors Part 4 – GPU Preemption Part 5 – Back To The Real World Part 6 – Experimenting With Overlap and […]
#### [Breaking Down Barriers – Part 3: Multiple Command Processors – The Danger Zone](https://mynameismjp.wordpress.com/2018/06/17/breaking-down-barriers-part-3-multiple-command-processors/ "") -
[…] a Barrier? Part 2 – Synchronizing GPU Threads Part 3 – Multiple Command Processors Part 4 – GPU Preemption Part 5 – Back To The Real World Part 6 – Experimenting With Overlap and […]