Position From Depth 3: Back In The Habit
A friend of mine once told me that you could use “back in the habit” as the subtitle for any movie sequel. I think it works.
So a lot of people still have trouble with reconstructing position from depth thing, judging by the emails I get and also the threads I see in the gamedev forums made by people who read my earlier blog posts. Can’t say I blame them…it’s pretty tricky, and easy to screw up. So I’m going to take it again from the beginning and try to explain some of the actual math behind the code, in hopes that a more generalized approach will help people get through the little quirks they’ll have to deal with in their own implementations. And I’ll throw some shader code in there too for good measure. Oh and I should mention that I’m going to do everything with a left-handed coordinate system, but it shouldn’t be hard to convert to right-handed.
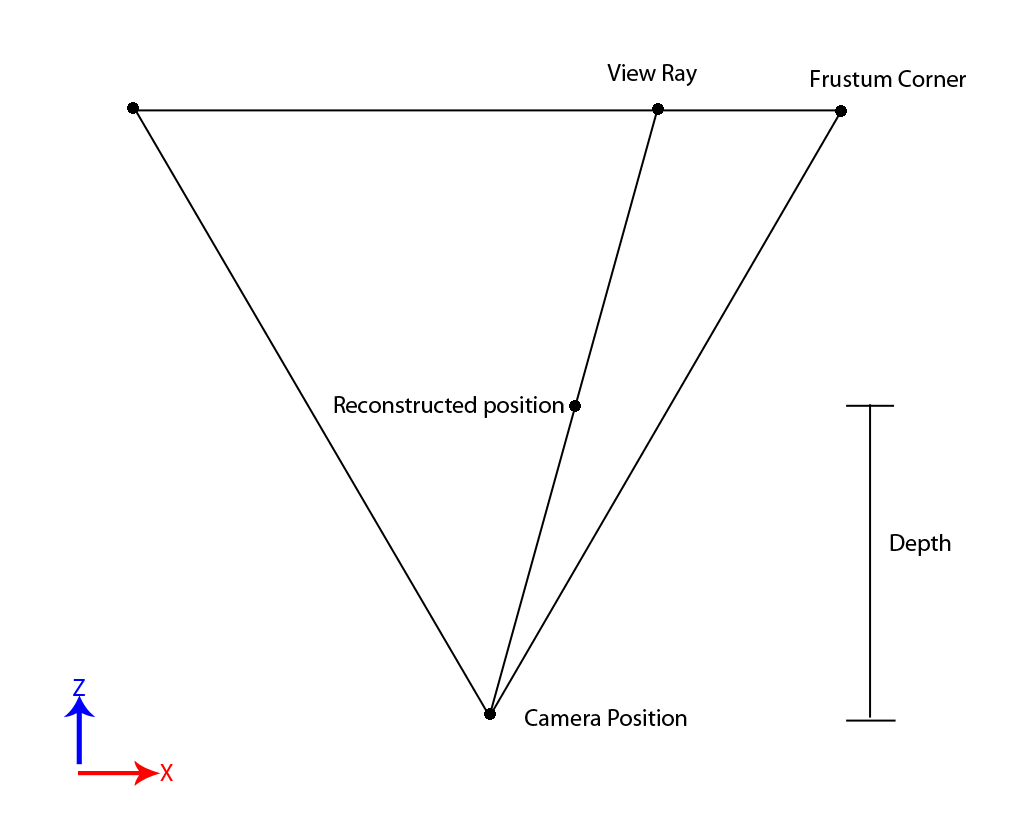
Let’s start with the basics of a perspective projection. For every pixel on the screen there’s a direction vector associated with it. You can figure out this direction vector by using the screen-space XY position of the pixel to lerp between the positions of the frustum corners, subtracting the camera position, and normalizing (you don’t have to subtract the camera position if you’re doing this in view space, since the camera position is 0). If geometry is rasterized at that pixel position, that means the surface at that pixel lies somewhere along that vector. The distance along that vector will vary depending on how far that geometry is from the camera, but the direction is always the same. This should sound familiar to anyone who’s written a ray tracer before, because it’s the exact concept used for primary rays: for a pixel on the near or far clip plane, get the direction from the camera to that pixel and check for intersections. What this ultimately means is that if we have the screen space pixel position and the camera position, we can figure out the position of the triangle surface if have the distance from the camera to the surface. Here’s an artfully-crafted diagram showing how this works:
 With this is mind, you might be thinking that if we stored the distance from the camera to the triangle surface in a G-Buffer pass then it would be really easy to reconstruct position from it. And you’d be totally right. The basic steps go like this:
With this is mind, you might be thinking that if we stored the distance from the camera to the triangle surface in a G-Buffer pass then it would be really easy to reconstruct position from it. And you’d be totally right. The basic steps go like this:
- In the pixel shader of the G-Buffer pass, calculate the distance from the camera to the surface being shaded and write it out to the depth texture
- In the vertex shader of the light pass, calculate the direction vector from the camera position to the vertex (we’ll call it the view ray).
- In the pixel shader, normalize the view ray vector
- Sample the depth texture to get the distance from the camera to the G-Buffer surface
- Multiply the sampled distance with the view ray
- Add the camera position
This is simple, cheap, and works in both view space and world space. In view space it’s a little cheaper and easier because the camera position is (0,0,0), so you can simplify the math. Plus the view ray is just the normalized view space position of the pixel. For a full-screen quad, you can get the view space position of the quad vertices either by directly mapping the verts to frustum corners, or by applying the inverse of your projection matrix. Then from there you can go back to world space if you want by applying the inverse of your view matrix (the camera world matrix). Here’s what the code might look like for doing it in world space (since people seem to like sticking to world space, despite the advantages of view space):
// G-Buffer vertex shader
// Calculate view space position of the vertex and pass it to the pixel shader
output.PositionVS = mul(input.PositionOS, WorldViewMatrix).xyz;
// G-Buffer pixel shader
// Calculate the length of the view space position to get the distance from camera->surface
output.Distance.x = length(input.PositionVS);
// Light vertex shader
#if PointLight || SpotLight
// Calculate the world space position for a light volume
float3 positionWS = mul(input.PositionOS, WorldMatrix);
#elif DirectionalLight
// Calculate the world space position for a full-screen quad (assume input vertex coordinates are in [-1,1] post-projection space)
float3 positionWS = mul(input.PositionOS, InvViewProjMatrix);
#endif
// Calculate the view ray
output.ViewRay = positionWS - CameraPositionWS;
// Light Pixel shader
// Normalize the view ray, and apply the original distance to reconstruct position
float3 viewRay = normalize(input.ViewRay);
float viewDistance = DistanceTexture.Sample(PointSampler, texCoord);
float3 positionWS = CameraPositionWS + viewRay * viewDistance;
Like I said it’s piece of cake, and I suspect that for a lot of people it’s efficient enough. But we’re not done yet, since we can still optimize things further if we stick to view space. We also want may want to use a hardware depth buffer as opposed to manually storing a distance value. So let’s dig deeper. Here’s a diagram showing another way of looking at the problem:

This time instead of using a normalized direction vector for the view ray, we extrapolate the ray all the way back until it intersects with the far clip plane. When we do this, it means that the position at the end of the view ray is at a known depth relative to the camera position and the direction the camera is looking (the depth is the far clip plane distance). In view space it means that the view ray has a Z component equal to the far clip plane. Since the Z component is a known value we no longer need to normalize the view ray vector. Instead we can multiply by a value that scales along the camera’s z-axis to get the final reconstructed position. In the case where Z = FarClipDistance, we want to scale by a ratio of the original surface depth relative to the far clip plane. In other words, the surface’s view space Z divided by the far clip distance. In code it looks like this:
{kind=link}
// G-Buffer vertex shader
// Calculate view space position of the vertex and pass it to the pixel shader
output.PositionVS = mul(input.PositionOS, WorldViewMatrix).xyz;
// G-Buffer pixel shader
// Divide view space Z by the far clip distance
output.Depth.x = input.PositionVS.z / FarClipDistance;
// Light vertex shader
#if PointLight || SpotLight
// Calculate the view space vertex position
output.PositionVS = mul(input.PositionOS, WorldViewMatrix);
#elif DirectionalLight
// Calculate the view space vertex position (you can also just directly map the vertex to a frustum corner
// to avoid the transform)
output.PositionVS = mul(input.PositionOS, InvProjMatrix);
#endif
// Light Pixel shader
#if PointLight || SpotLight
// Extrapolate the view space position to the far clip plane
float3 viewRay = float3(input.PositionVS.xy * (FarClipDistance / input.PositionVS.z), FarClipDistance);
#elif DirectionalLight
// For a directional light, the vertices were already on the far clip plane so we don't need to extrapolate
float3 viewRay = input.PositionVS.xyz;
#endif
// Sample the depth and scale the view ray to reconstruct view space position
float normalizedDepth = DepthTexture.Sample(PointSampler, texCoord).x;
float3 positionVS = viewRay * normalizedDepth;
As you can see this is a bit cheaper, especially for the full-screen quad case. One thing to be aware of is that since with this we store normalized depth, it’s always in the range [0,1]. This means you can store it in a normalized integer format (such as DXGI_FORMAT_R16_UNORM) without having to do any rescaling after you sample it. A floating point format will obviously handle it just fine as well.
Now let’s say we want to sample a hardware depth buffer instead of writing out our own depth or distance value to the G-Buffer. This makes sense in a lot of cases, since you’re already using the memory and bandwidth to fill the depth buffer so you might as well make use of it. A hardware depth buffer will store the post-projection Z value divided by the post-projection W value, where W is equal to the view-space Z component of the surface position (for more information see this). This makes the value initially unsuitable for our needs, but fortunately it’s possible to recover the view-space Z from this using the parameters of the perspective projection. Once we do that, we can convert it to a normalized depth value if we want and proceed normally. However this is unnecessary. Instead of extrapolating the view ray to the far clip plane, if we instead clamp it to the plane at Z = 1 we can then scale it by the view space Z without having to manipulate it first. Here’s the code:
// Light vertex shader
#if PointLight || SpotLight
// Calculate the view space vertex position
output.PositionVS = mul(input.PositionOS, WorldViewMatrix);
#elif DirectionalLight
// For a directional light we can clamp in the vertex shader, since we only interpolate in the XY direction
float3 positionVS = mul(input.PositionOS, InvProjMatrix);
output.ViewRay = float3(positionVS.xy / positionVS.z, 1.0f);
#endif
// Light Pixel shader
#if PointLight || SpotLight
// Clamp the view space position to the plane at Z = 1
float3 viewRay = float3(input.PositionVS.xy / input.PositionVS.z, 1.0f);
#elif DirectionalLight
// For a directional light we already clamped in the vertex shader
float3 viewRay = input.ViewRay.xyz;
#endif
// Calculate our projection constants (you should of course do this in the app code, I'm just showing how to do it)
ProjectionA = FarClipDistance / (FarClipDistance - NearClipDistance);
ProjectionB = (-FarClipDistance * NearClipDistance) / (FarClipDistance - NearClipDistance);
// Sample the depth and convert to linear view space Z (assume it gets sampled as
// a floating point value of the range [0,1])
float depth = DepthTexture.Sample(PointSampler, texCoord).x;
float linearDepth = ProjectionB / (depth - ProjectionA);
float3 positionVS = viewRay * linearDepth;
It’s also possible to use a hardware depth buffer with the first method, if you want to work in an arbitrary coordinate space. The trick is to project the view ray onto the camera’s z axis (AKA the camera’s forward vector or lookAt vector), and use that to figure out a proper scaling value. The light pixel shader goes something like this:
// Normalize the view ray
float3 viewRay = normalize(input.ViewRay);
// Sample the depth buffer and convert it to linear depth
float depth = DepthTexture.Sample(PointSampler, texCoord).x;
float linearDepth = ProjectionB / (depth - ProjectionA);
// Project the view ray onto the camera's z-axis
float viewZDist = dot(EyeZAxis, viewRay);
// Scale the view ray by the ratio of the linear z value to the projected view ray
float3 positionWS = CameraPositionWS + viewRay * (linearDepth / viewZDist);
Alright, so I think that’s about it! If anything is unclear or if I made any mistakes, go ahead and let me know. For an actual working sample showing some of these techniques, you can have a look at the sample for my article on depth precision.
02/23/1985 - Fixed typo in view space volume reconstruction
Comments:
skytiger -
and another: – Vertex Shader – Output.Ptrick = Pproj.xyw; – Pixel Shader – float4x4 matProj; // standard projection matrix static const float2 Clever = 1.0 / matProj._11_22; Ptrick.xy /= Ptrick.z; Ptrick.xy *= Clever * LinearZ; Ptrick.z = LinearZ;
#### [richard osborne](http://www.kreationsedge.com "rosborne255@yahoo.com") -
Ah, now that makes perfect sense. I’ve been sticking with DirectX 9 primarily. I’ll have to look into playing around with DirectX 11
#### [skytiger](http://skytiger.wordpress.com "corbin@skymo.com") -
Here is another approach, using VPOS: // Effect Parameters float4x4 matProj; // standard projection matrix float2 fTargetSize; // rendertarget pixel dimensions // Can calculate this on CPU side static const float3x3 matVPosToView = float3x3( 2.0 / fTargetSize.x / matProj._11, 0, 0 , 0, -2.0 / fTargetSize.y / matProj._22, 0 , -1.0 / matProj._11, 1.0 / matProj._22, 1 );//float3x3 // Usage in Pixel Shader: struct PixIn { float2 vpos : VPOS; };//struct float3 Pview; Pview.xy = mul(float3(Input.vpos, 1), matVPosToView).xy; Pview.xy *= LinearZ; Pview.z = LinearZ;
#### [When Position-From-Depth Goes Bad « gpubound](http://gpubound.wordpress.com/2011/01/30/when-position-from-depth-goes-bad/ "") -
[…] 0 If you’ve ever had to reconstruct position from depth, you’ve probably come across one of these methods where you send an interpolated view-ray from the vertex shader down to the pixel shader, where you […]
#### [Me]( "egea.hernando@gmail.com") -
Thank you very much indeed!! I got deferred lighting working perfectly thanks to your article. I save the normals and linear depth in a 32 BIT FLOAT and I reconstruct thee ViewSpace coordinates from it. I’m new in GLSL so it took me some hits of my head against the wall. I like the idea of the deferred lighting for dynamic lights, pretty simple. There are a lot of subtleties, but here come my GLSL shaders: http://pastebin.com/XmXGx2rz And a screenshot: http://img824.imageshack.us/i/pantallazovg.png/
{kind=link}
#### [Position From Depth, GLSL Style « The Danger Zone](http://mynameismjp.wordpress.com/2011/01/08/position-from-depth-glsl-style/ "") -
[…] his GLSL implementation of a deferred point light shader, which makes use of one of the methods I previously posted for reconstructing position from depth. So I figured I’d post it here, for all of you […]
#### [mpettineo](http://mynameismjp.wordpress.com/ "mpettineo@gmail.com") -
No, that’s correct. You want your linear view-space Z value divided by the distance to your far clipping plane.
#### [mpettineo](http://mynameismjp.wordpress.com/ "mpettineo@gmail.com") -
Hi Richard, I’ve been using D3D11 lately, and that lets you natively access a depth buffer without any vendor hacks through shader resource views and typeless formats. I do actually use that technique in the “attack of the depth buffer” sample. If you’re using the D3D9 vendor hacks (INTZ and friends) the math in the shader code ends up being exactly the same, since those also give you the depth as a [0,1] floating point value.
#### [quantumryan](http://ryangogame.blogspot.com/ "quantumryan@gmail.com") -
I just wanted to say thank you. Although this wasn’t exactly what I was looking for, you’re figures gave me the ah-ha moment I needed. I wrote a two color depth shader and I dump a stream of images of my 3D scene. I wrote python script to convert pixel data into camera local position data. My trig was all right, but I was using the actual computed depth instead of the projected image depth (the far). Doh! Awesome stuff. I’m following your blog now. Keep it up please!
#### [richard osborne](http://www.kreationsedge.com "rosborne255@yahoo.com") -
Hey MJP- just curious how are you getting access to the hardware depth buffer? Are you using driver hacks to access it (for instance, with nvidia cards I thought we had to use a depth texture)? Cant recall if you code sample included with “Attack of the Depth Buffer” included this
#### [Tiago Costa]( "tiago.costav@gmail.com") -
I calculate the corners following a website that you posted a link to: float Hfar = 2 * tan(fov / 2) * zFar; float Wfar = Hfar * ratio; D3DXVECTOR3 farCenter = mPosition + mLook * zFar; D3DXVECTOR3 farTopLeft = farCenter + (mUp * Hfar/2) - (mRight * Wfar/2); D3DXVECTOR3 farTopRight = farCenter + (mUp * Hfar/2) + (mRight * Wfar/2); D3DXVECTOR3 farDownLeft = farCenter - (mUp * Hfar/2) - (mRight * Wfar/2); D3DXVECTOR3 farDownRight = farCenter - (mUp * Hfar/2) + (mRight * Wfar/2); Can I use this frustum corners to reconstruct pixel position in view-space or world-space?
#### [mpettineo](http://mynameismjp.wordpress.com/ "mpettineo@gmail.com") -
Hey Tiago, Like I said in the post the frustum corners are only useful if you want to save a little bit of vertex calculation for a full screen quad. You can get the same results just by using the inverse of your projection matrix, which is easier and less error-prone. And since you have only 4 verts per quad, the extra cost is negligable.
#### [Tiago Costa]( "tiago.costav@gmail.com") -
I know that the extra cost in negligible, but as my game engine is GPU bound Im trying to move some calculations to the CPU…
#### [Tiago Costa]( "tiago.costav@gmail.com") -
Thank you for at least trying to help people that like me have found that reconstruct the pixel position from depth can be really hard… I’m already able to reconstruct the pixel position following your hold posts but the results arent completely correct… Right now I’m doing a major update in my game engine, and once I finish it I will re-implement pixel position reconstruction following this post and maybe it will work correctly this time :D
#### [empiricu]( "") -
I don´t know why the next code not work; vertex_position.z is the z in view-space. float3 eye; IN.coord.x = ( IN.coord.x * 2.0 ) / screeWidth - 1.0; IN.coord.y = ( IN.coord.y * 2.0 ) / screenHeight - 1.0; eye.x = IN.coord.x * ( WFarClip / 2.0 ); eye.y = -IN.coord.y * ( HFarClip / 2.0 ); eye.z = Far; eye = normalize(eye); // normalize viewray // vertex_position.xyz = a * eye.xyz; // a = vertex_position.z / eye.z vertex_position.x = ( vertex_position.z / eye.z ) * eye.x; vertex_position.y = ( vertex_position.z / eye.z ) * eye.y;
#### [kaos]( "") -
output.PositionVS = mul(input.PositionOS, WorldViewMatrix).xyz; output.Depth.x = input.PositionVS.z / FarClipDistance; WorldViewMatrix not is WorldViewProjectionMatrix so I think input.PositionVS.z / FarClipDistance not is correct.
#### []( "") -
Multiply your result with the inverse view matrix.
#### [lipsryme]( "") -
Hi, I’ve stored my depth in linear view space using viewpos.z / farClip and retrieving viewspace position with the viewRay * Depth but my point lights still move around with the camera and appear/vanish when I get closer/farther away. Normals are in view space. Works flawless when I use z/w depth but I can’t get it to work with linear view space depth. Any suggestions ?
#### [Pretender]( "") -
Hi I’m in trouble with fullscreen quads worldpos reconstruct. My quad’s vertices are in [{-1,-1};{1,1}] and when I transform this position with the invViewProj, the result is wrong. What’s the problem? What is the input position’s z coordinate? Thanks
#### [MJP](http://mynameismjp.wordpress.com/ "mpettineo@gmail.com") -
Z and W should both be 1.0 for a fullscreen quad.
#### [EO]( "dominicstreeter@hotmail.com") -
Thank you for your depth tutorials they are a great starting point but I am still working through them, one of the weirdest things is how many different linearisation algorithms I have seen just for openGL: http://www.geeks3d.com/20091216/geexlab-how-to-visualize-the-depth-buffer-in-glsl/ That one worked for me and by extrapolation from your second from last code snippet: projectionMatrixNFLinearScalar.set((far + near) / (far - near), (2 * near) / (far - near)); - gave me: float linearDepth = projNFLinearScalarB / (projNFLinearScalarA - depth); I have no idea why working solution differs so much from the others I have seen, projections and notation being identical… I am for now baffled.
#### [Tyler Wozniak](http://gravatar.com/ttw6741 "ttw6741@rit.edu") -
So I’m currently working on a deferred rendering engine in D (you can find it at https://github.com/Circular-Studios/Dash, but that’s not that important). I’m trying to rebuild the Z position using the technique you described in your second-last code sample, with the hardware depth buffer and the two projection constants. However, I was getting a final viewspace position that I had to invert in order to properly calculate the eye-direction for my specular component. So I went to the website you linked here http://www.sjbaker.org/steve/omniv/love_your_z_buffer.html to check the origin of the projection constants, and solving for Z in the equation there, it seems like the final depth formula should be ProjectionB / ( ProjectionA - depth ), rather than the way you wrote it. Am I missing something here? Switching the two values gave specular highlights that seem correct for me, so it seems like it worked, but I want to make sure I’m understanding correctly. Also, thanks for the great tutorials!
#### [Performance update with tutorial - Celelej Game Engine](http://celelej.com/performance-update-1/ "") -
[…] so why don’t peek data from it? Here is very good tutorial how reconstruct position from it: link. When talking about GBuffer itself, I must also say something about normal vectors storage. As I […]
#### [MJP](http://mynameismjp.wordpress.com/ "mpettineo@gmail.com") -
Hi Tyler, I’m pretty sure the issue here is just LH vs RH conventions for OpenGL and DX. By convention, in DirectX you usually have your view space coordinate system setup such that Z+ is in front of the camera, whereas in OpenGL most people will set up their projection such that Z- is in front of the camera. Consequently in the projection matrix there’s an extra negative for the OpenGL case to make sure that the result ends up being positive, which is why the depth equation is slightly different if you write it out in terms of ProjectionA and ProjectionB. If you don’t want to make assumptions about your coordinate system inside your shader code, you should be able to do things directly in terms of your actual projection matrix instead of using the A and B constants: linearZ = Projection._43 / (zw - Projection._33) assuming that you’re using a row-major projection matrix.
#### [Linear Surface Features on Dynamic Terrain | Phillip Hamlyn](http://philliphamlyn.wordpress.com/2014/04/08/linear-surface-features-on-dynamic-terrain/ "") -
[…] already been drawn. The maths of this method are covered in the excellent series of articles by MJP – Position From Depth. The basic method […]
#### [EO]( "dominicstreeter@hotmail.com") -
So my solution was this : projectionMatrixNFLinearScalar.set((2 * near) / (far - near), (far + near) / (far - near)); x = 0.000266702, y = 1.0002667 Projection matrix looks like this (near 2 far 15000): 0.95209867 0.0 0.0 0.0 0.0 1.428148 -0.0 0.0 0.0 0.0 -1.0002667 -4.0005336 0.0 0.0 -1.0 0.0 Literal extrapolation of values from projection based on Projection._43 / (zw – Projection._33): projectionMatrixNFLinearScalar.set((projectionMatrix.m32+2*near)*-1, projectionMatrix.m22*-1); The above works as a quick fix, but my first solution yields a marginally different first value. Here is the code used to create the projection: public static void createProjection(Matrix4f projectionMatrix, float fov, float aspect, float znear, float zfar) { float scale = (float) Math.tan((Math.toRadians(fov)) * 0.5f) * znear; float r = aspect * scale; float l = -r; float t = scale; float b = -t; projectionMatrix.m00 = 2 * znear / (r-l); projectionMatrix.m01 = 0; projectionMatrix.m02 = 0; projectionMatrix.m03 = 0; projectionMatrix.m10 = 0; projectionMatrix.m11 = 2 * znear / (t-b); projectionMatrix.m12 = 0; projectionMatrix.m13 = 0; projectionMatrix.m20 = (r + l) / (r-l); projectionMatrix.m21 = (t+b)/(t-b); projectionMatrix.m22 = -(zfar + znear) / (zfar-znear); projectionMatrix.m23 = -1; projectionMatrix.m30 = 0; projectionMatrix.m31 = 0; projectionMatrix.m32 = -2 * zfar * znear / (zfar - znear); projectionMatrix.m33 = 0; } Shader: float linearDepth = projNFLinearScalarA / (projNFLinearScalarB - depth); This has me questioning the legitimacy of my projection matrix, projection works perfectly and I can solve linear depth but I am afraid I may hit further issues down the line trying to solve world space using methods you have shown. Note that I am using right handed notation in openGL, can anyone qualify any flaw in the code above? Thanks, EO
#### [Screen Space Glossy Reflections | Roar11.com](http://roar11.com/2015/07/screen-space-glossy-reflections/ "") -
[…] [6] Matt Pettineo. https://mynameismjp.wordpress.com/2010/09/05/position-from-depth-3/ […]
#### [opengl – Calculating shadowmap coordinates for cubemap in shading pass? | Asking](http://www.faceyoutub.com/game-development/opengl-calculating-shadowmap-coordinates-for-cubemap-in-shading-pass.html "") -
[…] use a cube map for shadows you need to recreate the world position of the pixel you are rendering and from that get the normal that points at that world position from […]
#### [[Перевод] Learn OpenGL. Урок 5.10 – Screen Space Ambient Occlusion - Новини дня](http://ukr-news.ml/2018/08/%d0%bf%d0%b5%d1%80%d0%b5%d0%b2%d0%be%d0%b4-learn-opengl-%d1%83%d1%80%d0%be%d0%ba-5-10-screen-space-ambient-occlusion "") -
[…] магии, что описано, например, у Matt Pettineo в блоге. Это, конечно, требующий бОльших затрат на расчеты […]
#### [How can I find the pixel space coordinates of a 3D point – Part 3 – The Depth Buffer – Nicolas Bertoa](https://nbertoa.wordpress.com/2017/01/21/how-can-i-find-the-pixel-space-coordinates-of-a-3d-point-part-3-the-depth-buffer/ "") -
[…] position from depth in deferred shading techniques (Matt Pettineo explains this in detail in this article). Here you have an hlsl code to get Zv from […]
#### [DirectX 12 Engine- Updates + Demo – Nicolas Bertoa](https://nbertoa.wordpress.com/2016/10/28/directx-12-engine-updates-demo/ "") -
[…] I was creating an additional geometry buffer to store depth in view space. I followed an article to reuse the already existent depth stencil buffer […]